|
|
AJAX/JavaScript Enabled Parsing with Apache Nutch and Selenium
Web Crawling with Apache Nutch
Nutch is an open-source large scale web crawler which is now based on the MapReduce paradigm. I won’t get too deep into the specifics, as there’s a really great article on Gigaom that describes Nutch’s history in a bit more depth; but, work on Nutch originally began back in 2002 by, “then-Internet Archive search director Doug Cutting and University of Washington graduate student Mike Cafarella.” Over the course of the next few years, Yahoo! would hire Cutting and ‘split’ the Hadoop project out of nutch.
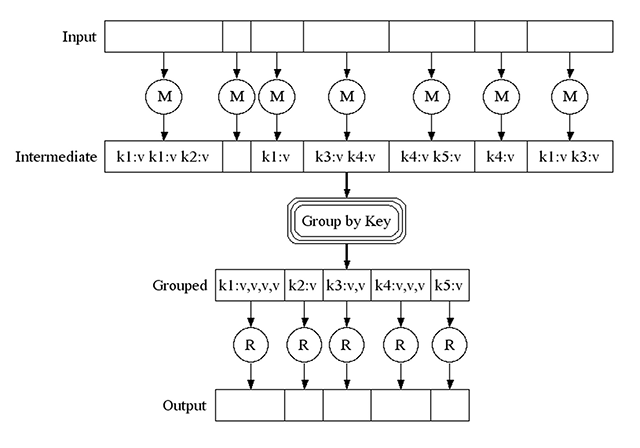
MapReduce: Simplified Data Processing on Large Clusters - Google
Nutch became an Apache incubator project in 2005, and a Top Level project in 2010; and, thanks to many committers’ work, you can be up and running a large scale web crawl within just a few minutes of downloading the source. Sidenote: See the Nutch 1.x tutorial for a more user-friendly tutorial.
Ungraceful Degredation and Empty Document Woes
After reading the above, you’re probably pretty excited to download Nutch, donate some money to Apache, and start a large scale web crawl; and, you should be! Let’s imagine that you run off and start a crawler immediately. Once the crawler has been running for a while, you might decide to start doing some analysis on your truly awesome set of documents only to find out that
A) Some websites seem to have the same content for each page
B) That content looks pretty much exactly like the static areas of the site that don’t change
- Header nav
- Sidebar
- Footer
C) Despite Twitter’s announcement that deferring JavaScript execution until content has been rendered improves performance and user experience, many developers (including myself at times with AngularJS) throw graceful degredation and progressive enhancement out of the window in favor of the “Too bad, enable JavaScript” pattern.
Wait a second, though, there’s no way that many sites are using
AJAX/JavaScript to load key bodies of content, right? They’d miss out on all
the SEO that you can tell they love, because they still stuff their
<meta name="keywords" /> tag despite
not using
Google Site Search, and Google not using it for their web rankings
anymore!
With a bit more Googling, you stumble across a Google Webmasters document about AJAX Crawling, which describes a hack/workaround that Google suggests AJAX based websites implement in order to get properly crawled.
In opening up the source of some of the wacky pages, you discover that sure
enough, there’s a <meta name="fragment" content="!"> tag in the content. To
add to your good fortune, you see that someone has already put in some work to
patch in escaped_fragment following functionality into Nutch.
You’re so close, you can almost taste success.
Then, you head over to the site’s “HTML Snapshot” at
http://typicalajaxsite.com/#!key=value
only to find that they’ve improperly implemented Google’s recommended
hack/work-around. Now you’re back to square 1.

picture by Moyan Brenn on Flickr
JavaScript Parsing in Java
Maybe someone else has encountered this issue; and, since Nutch is designed to be pluggable, maybe they’ve even written a plugin for it! Additional searching reveals to you the closest solution to your problem: a lone plugin on github that made use of htmlunit, a “GUI-Less browser for Java programs.” That sounds just fine - you’ve already burned an hour+ just getting to this point, and figure that even with an acknowledgement from the htmlunit team that it provided, “fairly good JavaScript support (which is constantly improving)”, it might be worth a shot. Just a bit of tinkering was needed to get the plugin working with Nutch 2.2.1; so you set about re-crawling the problem sites.
And checking the Lucene index on Solr 2’s awesome web-gui reveals…
{kind=link}

picture by Atlantic Community on Flickr
No Dice.
Some sites used knockout.js, and, despite its best efforts, htmlunit just didn’t fit the bill.
So, where to from here? Well, it’d be really neat to make use of the v8 JavaScript Engine via either Rhino or the JNI as StackOverflow User Dhaivat Pandya mentions, but that seems like a pretty big yak to shave – not to mention that htmlunit already uses Rhino for the core of its JavaScript functionality, and that didn’t work.
Bummer.
This is where I was about a month ago, with a very tight deadline. My goal was to get Nutch parsing AJAX/JavaScript within a day or two, and, it didn’t seem like it would be an easy process.
Enter: Selenium
As someone who has and continues to write quite a bit of Ruby/Rails, I’d written a few tests and small-scale crawl scripts using the Selenium WebDriver. Selenium is, simply put by the authors, “a suite of tools specifically for automating web browsers.”
Typically, Selenium is used for automating testing for web applications; but, it can also be used to programmatically manipulate complex forms during e.g. repetitive web crawls. So, I quickly put together a plugin that relies on Selenium/Firefox to parse the JavaScript, and pass the content back down the Nutch toolchain.
Going back through the rigmarole of creating a Nutch plug-in based on Selenium stand-alone, adding the dependencies and compiling Nutch, running a crawl, and finally checking the Solr web-gui again reveals something great: the AJAX/JavaScript dependent content is being stored in my Lucene index! Take that “Post Graceful Degredation Era”.

picture by Evan Long on Flickr
Errors, File Descriptors, and Zombies - Oh My!
Things were good for about an hour. I noticed in top that my test box was
creating zombies at an alarming rate; and, they were not being reaped. I went
home a little annoyed, but remembered the next day how I’d read that a
Selenium Hub / Node (a.k.a. Selenium Grid) set-up would be self-maintaining in that the hub would remove
nodes which stopped responding, and accept them back into the hub/spoke
system if they re-registered and behaved.
One thing was sure: this is a good thing; and, definitely an improved design over opening/closing Firefox windows like they were going out of style.
Quickly, I put together two docker containers:
and a Nutch plugin to make use of the new set-up:
Started up my containers, and then started up Nutch. And was well on my way.
Almost.
Earlier, when I’d created and tried the Nutch-Selenium stand-alone
plugin/configuration, I was using a
python script to start off my Supervisor daemon in
the same fashion as this old version of a Docker Cassandra image
by using python’s run_service() function. After making the switch
to os.exec() as recommended by a pythonista on IRC, the parent PID of the
running Selenium Node process was switched from Python to Supervisord; and,
Supervisord’s subprocesses were able to heal themselves once again.
However, Firefox continued to cause issues; and, when asking Supervisord to kill
and restart the Selenium Node process didn’t resolve them, I settled on a very
hackish solution… I set a cron job to literally kill -9 Firefox
periodically.

picture by Nagesh Jayaraman on Flickr
Deep Breath
So, in practice, it all works fine. Every once in a while a few pages will respond with errors to Nutch due to Firefox being down, so that zombie issue still sort-of nags at me. However, even though it may not be the prettiest solution to cleaning up after Firefox, I’m still crawling tens of thousands of pages and getting their dynamically loaded content whether they break their own work-arounds or not. Eventually, due to my only crawling a specific set of sites, those errored out pages will get crawled; and, that fits my project’s requirements.
Mo